nf-core/scnanoseq
Single-cell/nuclei pipeline for data derived from Oxford Nanopore and 10X Genomics
1.0.0). The latest
stable release is
1.2.1
.
Introduction
This document describes the output produced by the pipeline. Most of the plots are taken from the MultiQC report, which summarises results at the end of the pipeline.
The directories listed below will be created in the results directory after the pipeline has finished. All paths are relative to the top-level results directory.
Pipeline overview
The pipeline is built using Nextflow and processes data using the following steps:
- Preprocessing
- Nanofilt - Read Quality Filtering and Trimming
- Barcode Calling
- BLAZE - Barcode caller
- Alignment
- Minimap2 - Long read alignment
- Alignment Post-processing
- Samtools - Sort and index alignments and make alignment qc
- Barcode Tagging - Barcode tagging with quality metrics and barcode information
- Barcode Correction - Barcode whitelist correction
- UMI Deduplication - UMI-based deduplication
- Feature-Barcode Quantification
- Other steps
- UCSC - Annotation BED file
- Quality Control
- Pipeline information - Report metrics generated during the workflow execution
Preprocessing
Nanofilt
Output files
<sample_identifier>/fastq/trimmed_nanofilt/*_filtered.fastq.gz: The post-trimmed fastq. By default this will be mostly quality trimmed.
Nanofilt is a tool used for filtering and trimming of long read sequencing data.
Barcode Calling
BLAZE
Output files
<sample_identifier>/blaze/blaze/*.bc_count.txt: This is a file containing each barcode and the counts of how many reads support it.blaze/*.knee_plot.png: The knee plot detailing the ranking of each barcode.blaze/*.putative_bc.csv: This file contains the naively detected barcode for each read.blaze/*.whitelist.csv: This is a list of the “true” barcodes detected for a sample. The length of the file should roughly match the expected amount of cells that is expected for the sample.
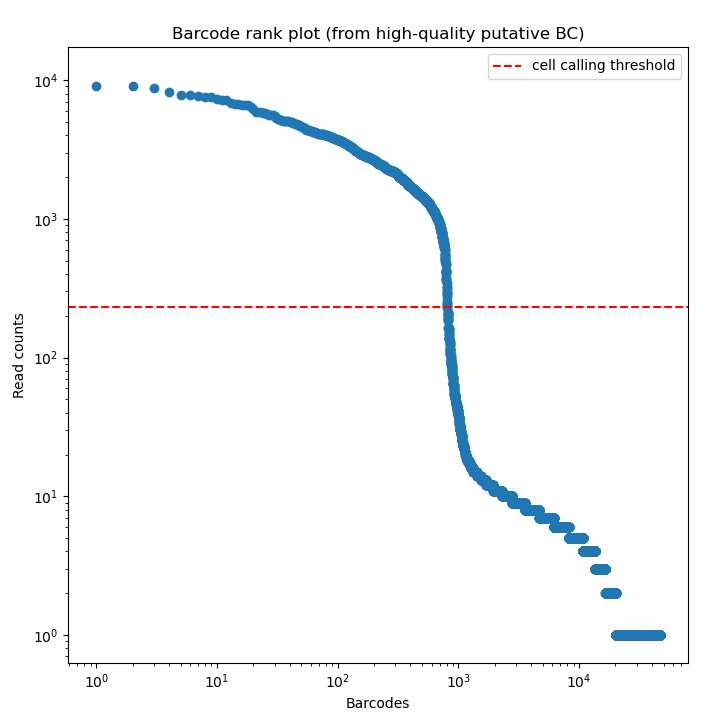
BLAZE enables the accurate identification of barcodes and UMIs from Nanopore reads. The files produced by BLAZE can be used to assess the quality of the barcode calling and the data.
The knee plot (an example is listed above) that is provided by BLAZE shows all barcodes detected in a sample, ranked from highest to lowest read count. The “cliff-and-knee” shape (similar to the image above) is indicative of good quality. Deviations from this shape can be indicative of concerns with the data, such as low barcode counts. The *.bc_count.txt file can be used to accompany this figure to show every barcode and its abundance in the dataset.
Alignment
Minimap2
Output files
<sample_identifier>/bam/original/*.sorted.bam: The mapped and sorted bam.*.sorted.bam.bai: The bam index for the mapped and sorted bam.
Minimap2 is a versatile sequence alignment program that aligns DNA or mRNA sequences against a large reference database. Minimap2 is optimized for large, noisy reads making it a staple for alignment of nanopore reads.
Alignment Post-processing
Samtools
Output files
<sample_identifier>/bam/mapped_only/*.sorted.bam: The bam contaning only reads that were able to be mapped.*.sorted.bam.bai: The bam index for the bam containing only reads that were able to be mapped.
qc/samtools/minimap/*.minimap.flagstat: The flagstat file for the bam obtained from minimap.*.minimap.idxstats: The idxstats file for the bam obtained from minimap.*.minimap.stats: The stats file for the bam obtained from minimap.
mapped_only/*.mapped_only.flagstat: The flagstat file for the bam containing only mapped reads.*.mapped_only.idxstats: The idxstats file for the bam containing only mapped reads.*.mapped_only.stats: The stats file for the bam containing only mapped reads.
corrected/*.corrected.flagstat: The flagstat file for the bam containing corrected barcodes.*.corrected.idxstats: The idxstat file for the bam containing corrected barcodes.*.corrected.stats: The stat file for the bam containing corrected barcodes.
dedup/*.dedup.flagstat: The flagstat file for the bam containing deduplicated umis.*.dedup.idxstats: The idxstats file for the bam containing deduplicated umis.*.dedup.stats: The stats file for the bam containing deduplicated umis.
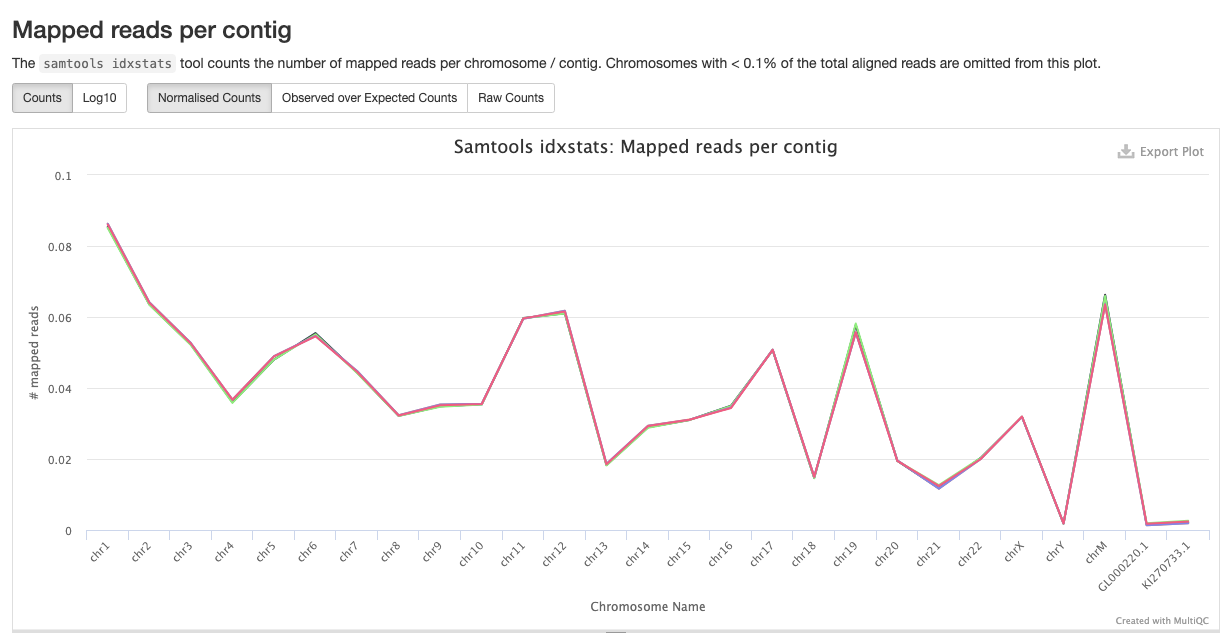
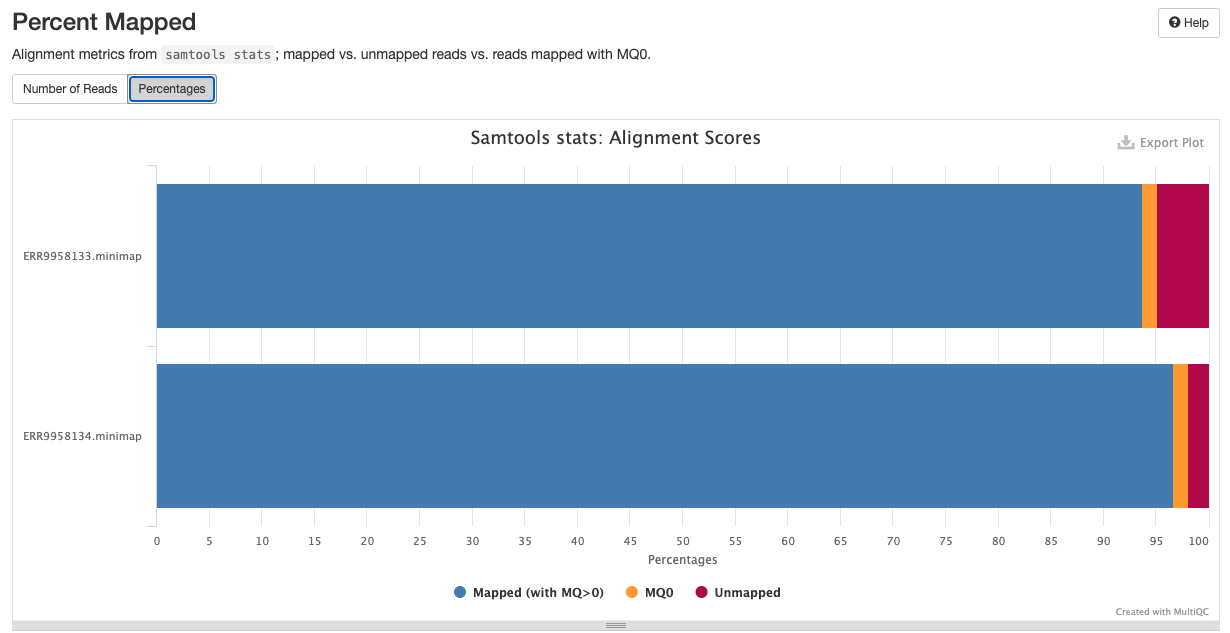
Samtools is a suite of programs for reading, writing, editing, indexing, and viewing files that are in SAM, BAM, or CRAM format
Barcode Tagging
Output files
<sample_identifier>/bam/barcode_tagged/*.tagged.bam: The bam containing tagged barcode and UMI metadata.
Barcode tagging is a custom script which adds metadata to the BAM files with commonly used single-cell tags which can be useful for custom down stream analysis (e.g.: subsetting BAMs based on cell barcodes). Specifically the following tags are added:
barcode tag = "CR"
barcode quality tag = "CY"
UMI tag = "UR"
UMI quality tag = "UY"Please see Barcode Correction below for metadata added post-correction.
Barcode Correction
Output files
<sample_identifier>/bam/corrected/*.corrected.bam: The bam containing corrected barcodes.*.corected.bam.bai: The bam index for the bam containing corrected barcodes.
Barcode correction is a custom script that uses the whitelist generated by BLAZE in order to correct barcodes that are not on the whitelist into a whitelisted barcode. During this step, an additional BAM tag is added, CB, to indicate a barcode sequence that is error-corected.
UMI Deduplication
Output files
<sample_identifier>/bam/dedup/*.dedup.bam: The bam containing corrected barcodes and deduplicated umis.*.dedup.bam.bai: The bam index for the bam containing corrected barcodes and deduplicated umis.
UMI-Tools deduplicate reads based on the mapping co-ordinate and the UMI attached to the read. The identification of duplicate reads is performed in an error-aware manner by building networks of related UMIs
Feature-Barcode Quantification
IsoQuant
Output files
<sample_identifier>/isoquant/*.gene_counts.tsv: The feature-barcode matrix from gene quantification.*.transcript_counts.tsv: The feature-barcode matrix from transcript quantification.
IsoQuant is a tool for the genome-based analysis of long RNA reads, such as PacBio or Oxford Nanopores. IsoQuant allows to reconstruct and quantify transcript models with high precision and decent recall. If the reference annotation is given, IsoQuant also assigns reads to the annotated isoforms based on their intron and exon structure. IsoQuant further performs annotated gene, isoform, exon and intron quantification. The outputs of IsoQuant can be important for downstream analysis with tools specialized in single-cell/nuclei analysis (e.g.: Seurat).
Seurat
Output files
<sample_identifier>/qc/gene/*.csv: A file containing statistics about the cell-read distribution for genes.*.png: A series of qc images to determine the quality of the gene quantification.
transcript/*.csv: A file containing statistics about the cell-read distribution for transcript.*.png: A series of qc images to determine the quality of the transcript quantification.
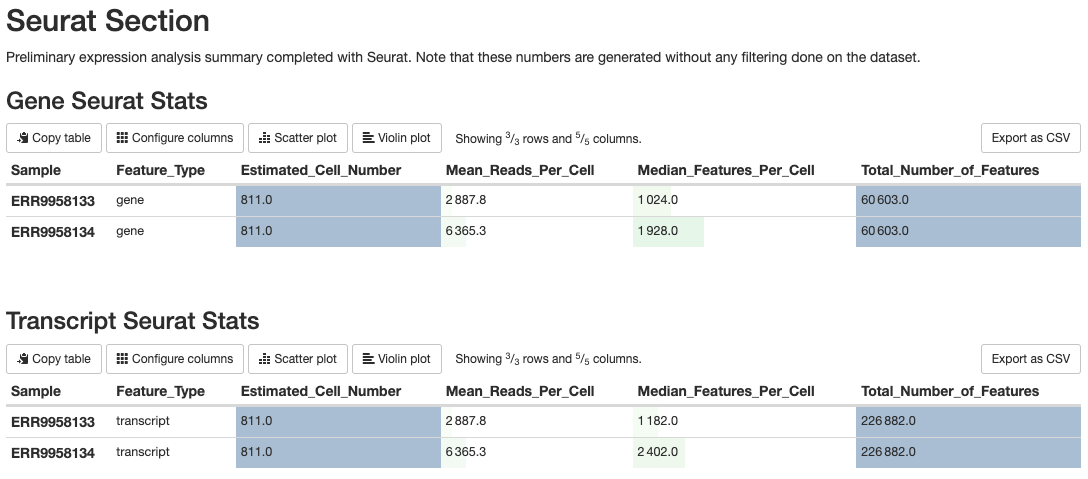 High level statistics are provided in the MultiQC report, as show in this image. These provide an overview of the quality of the data in order to assess if the results are suitable for tertiary analysis.
High level statistics are provided in the MultiQC report, as show in this image. These provide an overview of the quality of the data in order to assess if the results are suitable for tertiary analysis.
Seurat is an R package designed for QC, analysis, and exploration of single-cell RNA-seq data.
Other steps
UCSC
Output files
ucsc/*.annotation.bed: BED file format from input GTF*.annotation.genepred: genepred file format from input GTF
ucsc-gtftogenepred and ucsc-genepredtobed are stand-alone applications developed by UCSC which, together, converts a GTF file the BED file format.
Quality Control
FastQC
Output files
<sample_identifier>/qc/fastqc/pre_trim/andpost_trim/andpost_extract/*_fastqc.html: FastQC report containing quality metrics.*_fastqc.zip: Zip archive containing the FastQC report, tab-delimited data file and plot images.
FastQC gives general quality metrics about your sequenced reads. It provides information about the quality score distribution across your reads, per base sequence content (%A/T/G/C), adapter contamination and overrepresented sequences. For further reading and documentation see the FastQC help pages.
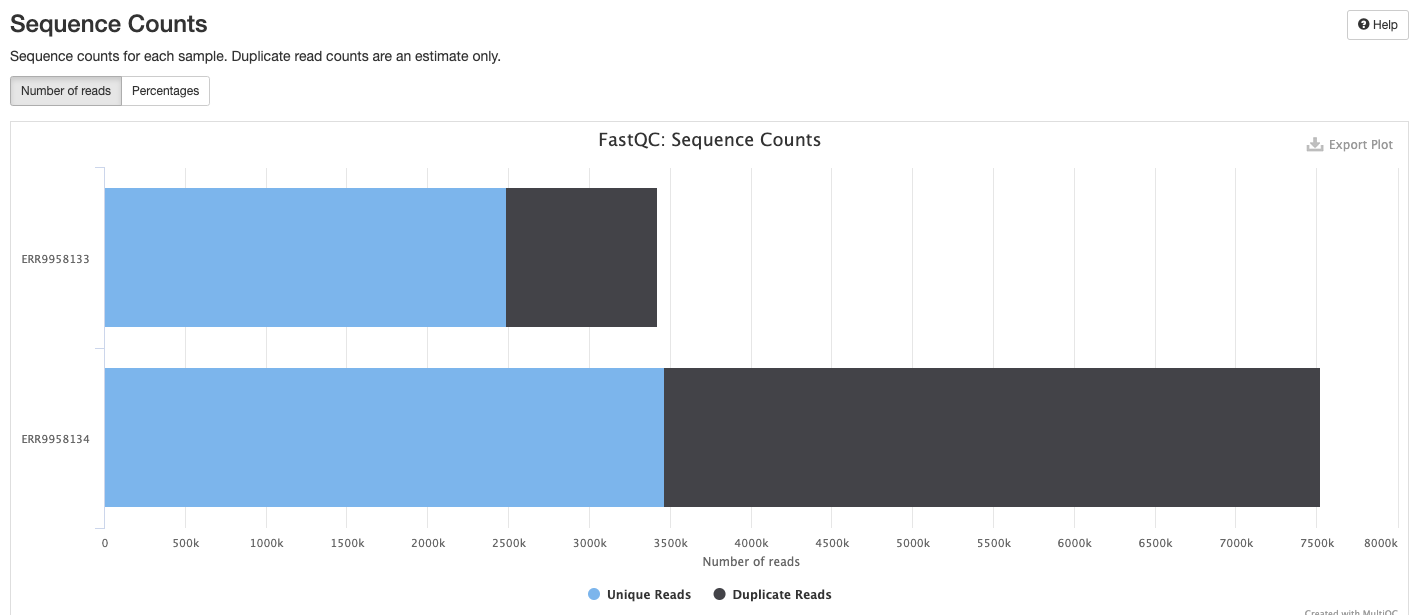
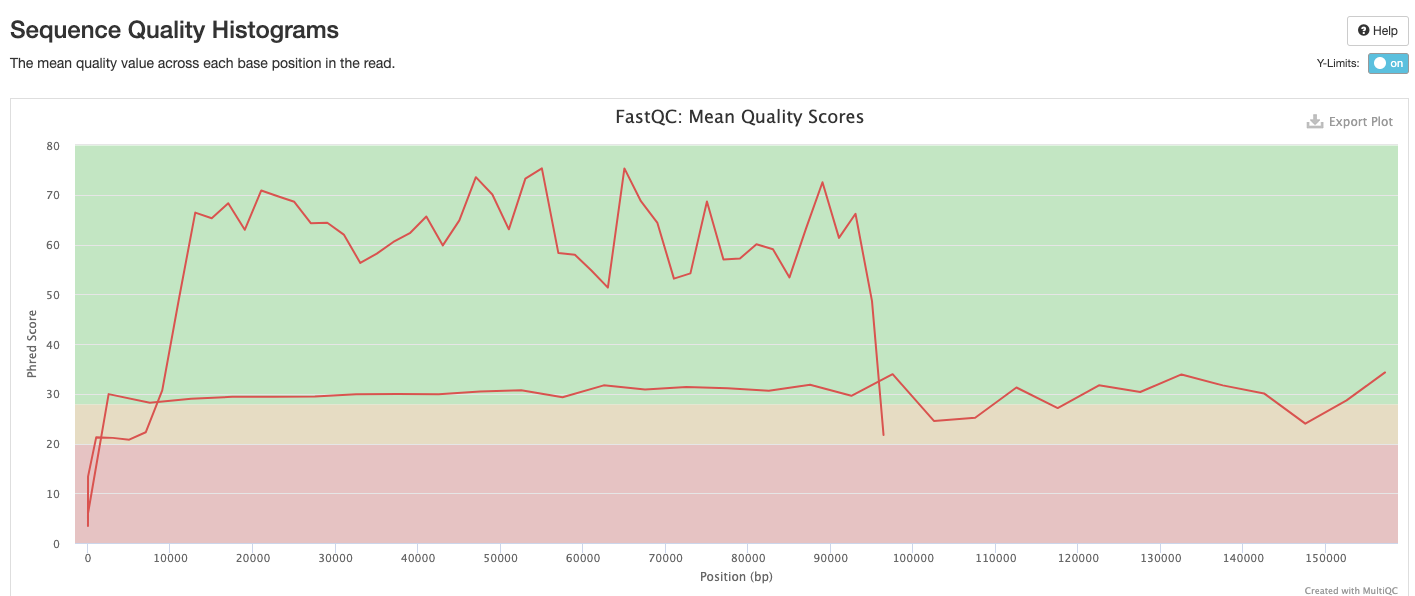
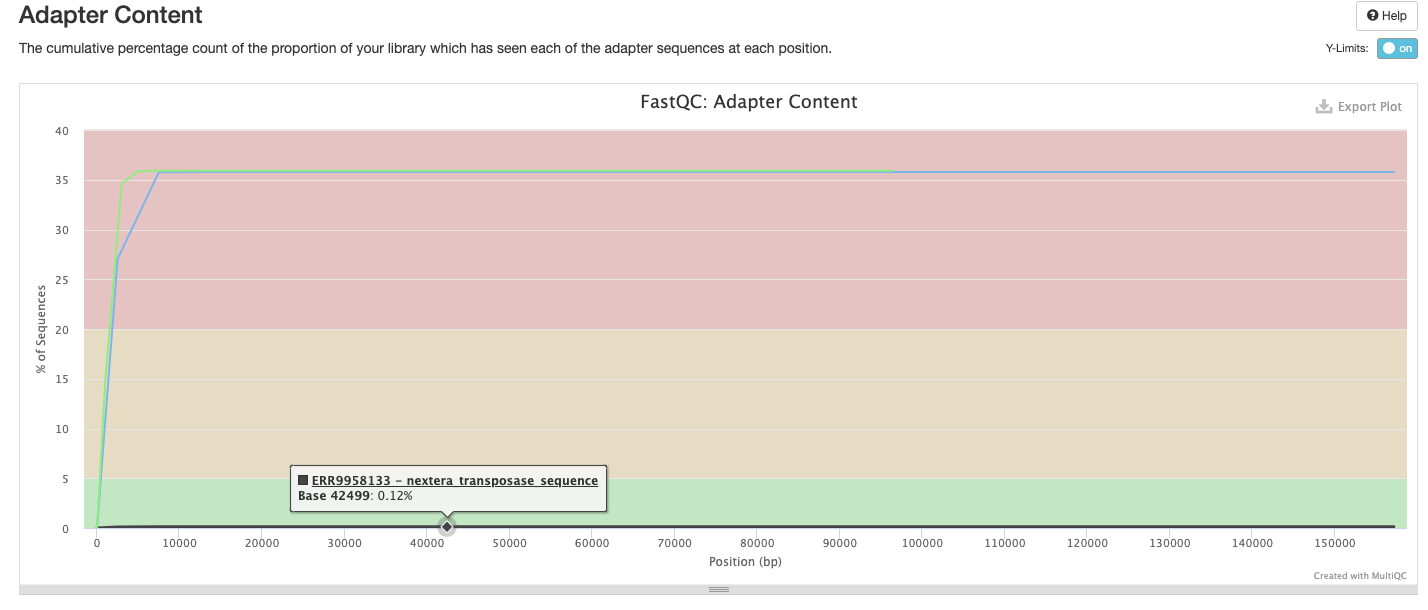
The FastQC plots displayed in the MultiQC report shows untrimmed reads. They may contain adapter sequence and potentially regions with low quality.
NanoComp
Output files
batch_qcs/nanocomp/fastq/andbam/NanoComp_*.log: This is the log file detailing the nanocomp run.NanoComp-report.html- This is browser-viewable report that contains all the figures in a single location.*.html: Nanocomp outputs all the figures in the report as individual files that can be inspected separately.NanoStats.txt: This file contains quality control statistics about the dataset.
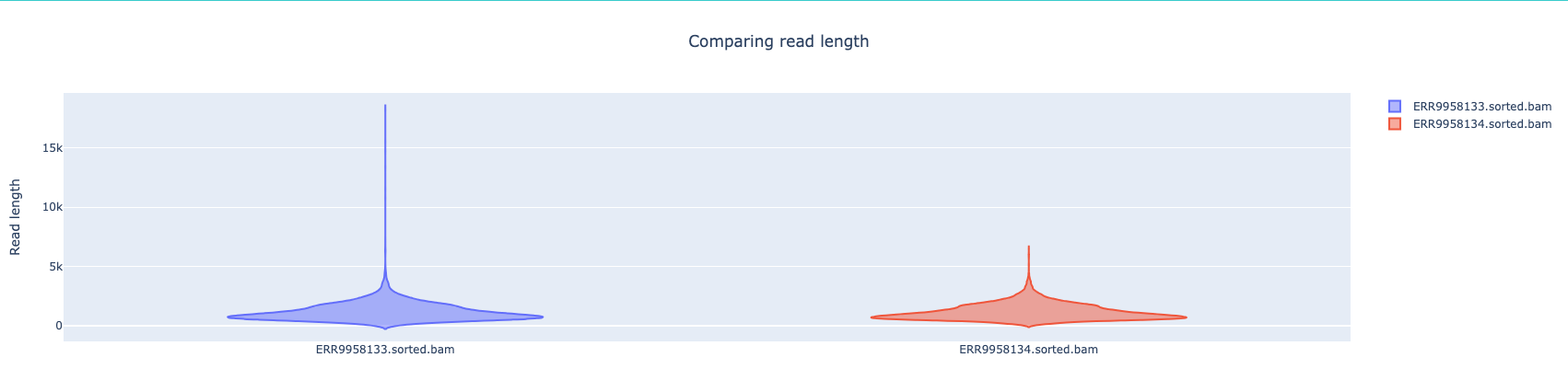
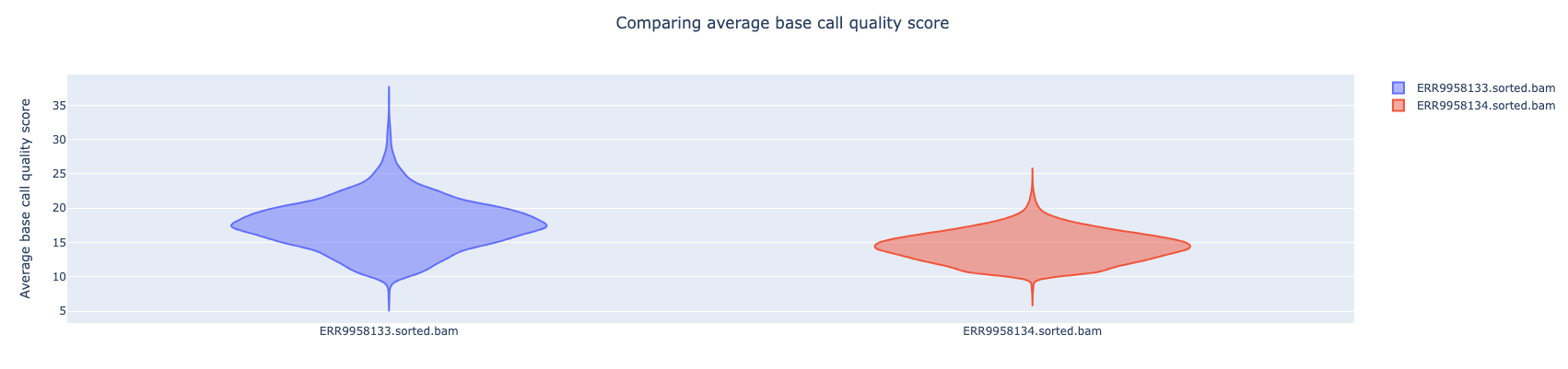
NanoComp compares multiple runs of long read sequencing data and alignments. It creates violin plots or box plots of length, quality and percent identity and creates dynamic, overlaying read length histograms and a cumulative yield plot
NanoPlot
Output files
<sample_identifier>/qc/nanoplot/pre_trim/andpost_trim/andpost_extract/NanoPlot_*.log: This is the log file detailing the nanoplot runNanoPlot-report.html- This is browser-viewable report that contains all the figures in a single location.*.html: Nanoplot outputs all the figures in the report as individual files that can be inspected separately.NanoStats.txt: This file contains quality control statistics about the dataset.NanoStats_post_filtering.txt: If any filtering metrics are used for nanoplot this will contain the differences. This is produced by default and should contain no differences fromNanoStats.txtif the process was unmodified
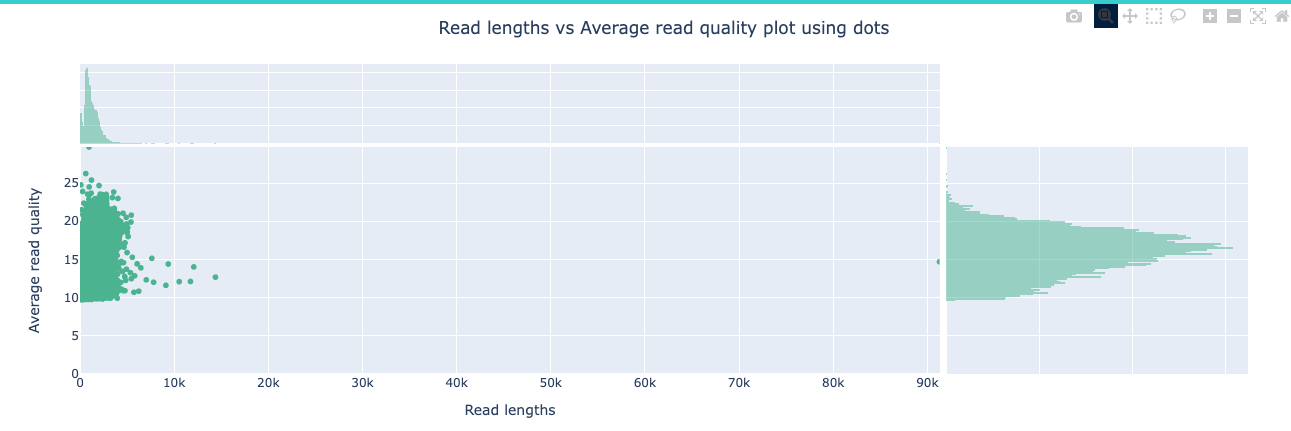
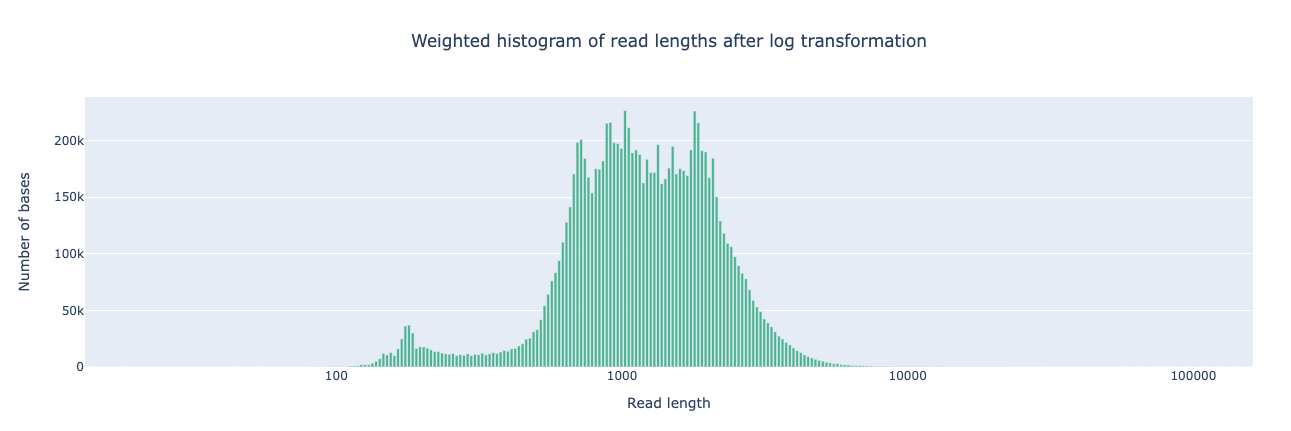
NanoPlot is a plotting tool for long read sequencing data and alignments.
ToulligQC
Output files
<sample_identifier>/qc/toulligqc/pre_trim/andpost_trim/andpost_extract/<sample_identifier>ToulligQC-report-<date>/report.html: This is browser-viewable report that contains all the figures in a single location.report.data: A log file containing information about ToulligQC execution, environment variables and full statisticsimages/*: This is folder containing all the individual images produced by ToulligQC
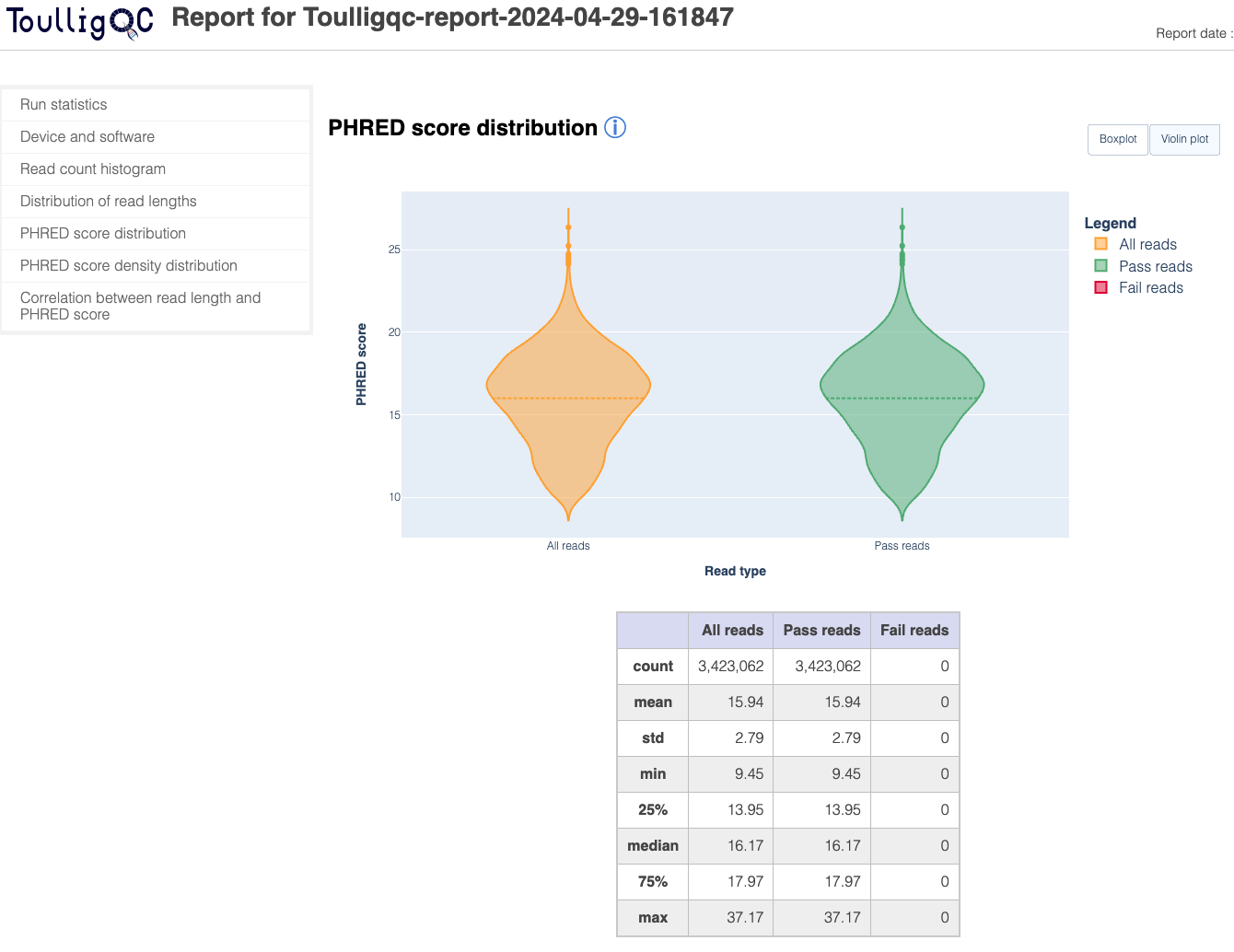
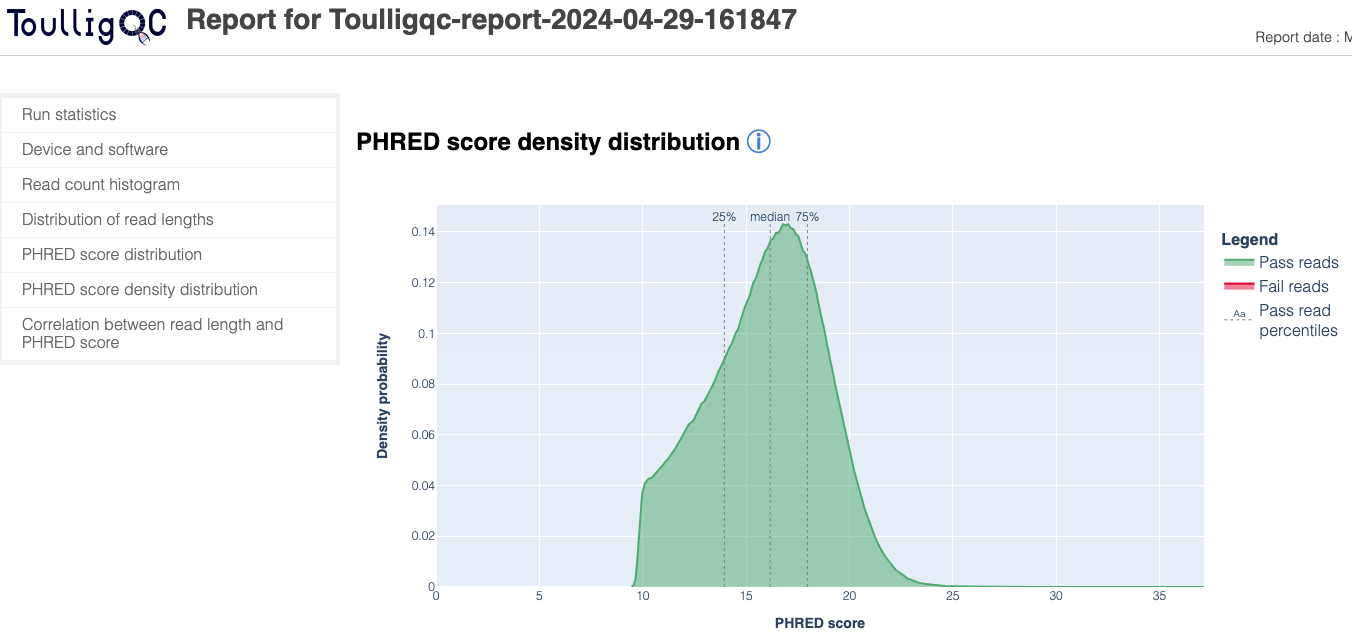
ToulligQC is a post sequencing QC tool for Oxford Nanopore sequencers.
RSeQC
Output files
<sample_identifier>/qc/rseqc/*.read_distribution.txt: This file contains statisitics noting the type of reads located within the dataset
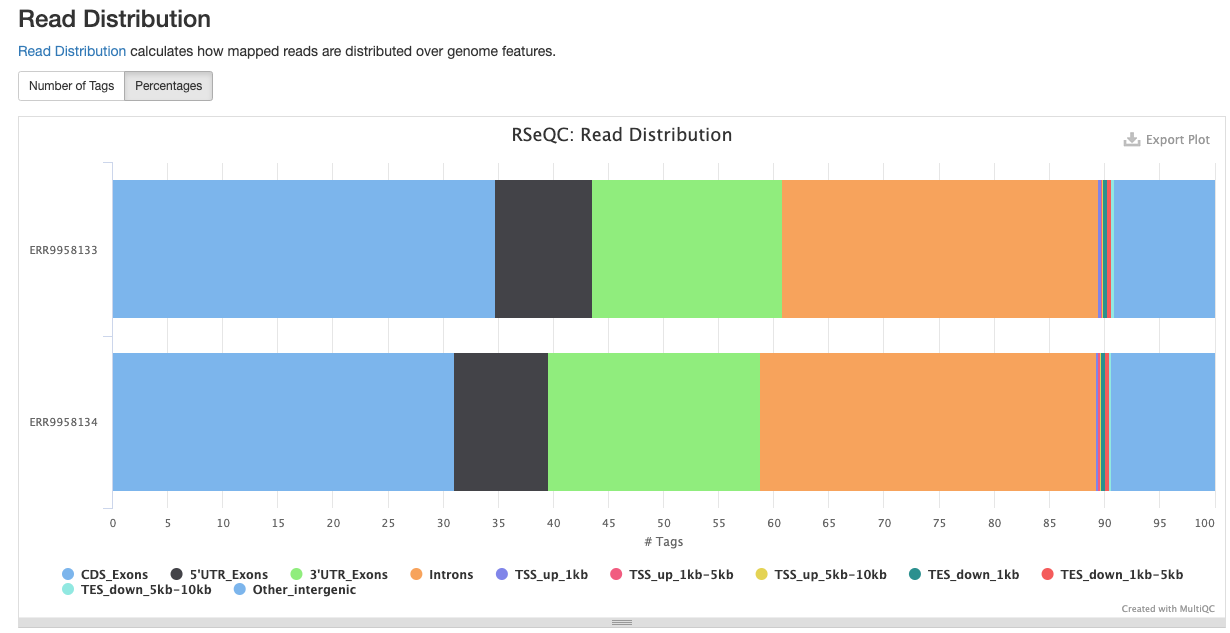
RSeQC package provides a number of useful modules that can comprehensively evaluate high throughput sequence data especially RNA-seq data.
Read Counts
Output files
batch_qcs/read_counts/read_counts.csv: This file contains the read counts for each sample at various points in the pipeline. Each row is a different sample, and the columns are the amount of reads the sample contained at that point in the pipeline.
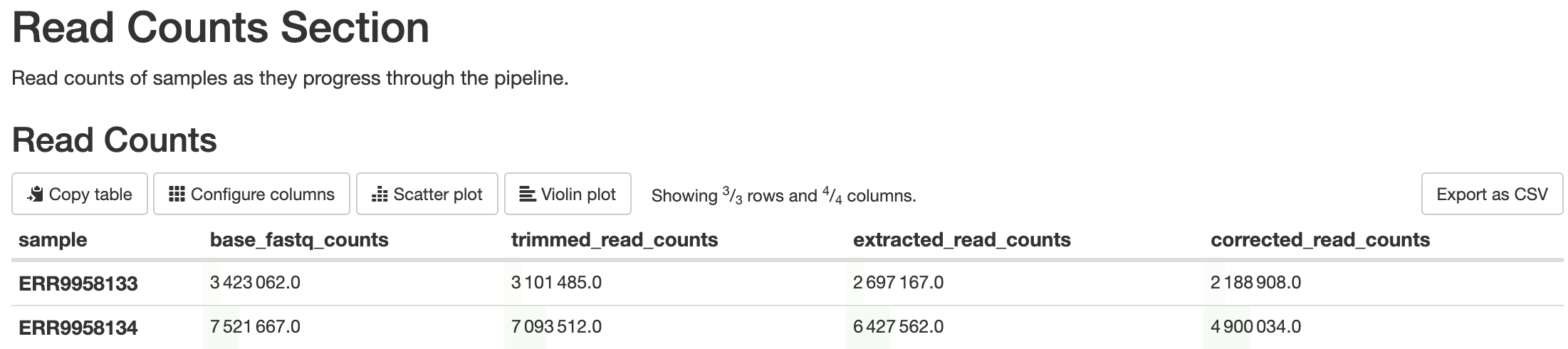
This is a custom script written using BASH scripting. Its purpose is to report the amount of reads that are filtered out at steps in the pipeline that will result in filtered reads, such as barcode detection, barcode correction, alignment, etc. Elevated levels of filtering can be indicative of quality concerns.
MultiQC
Output files
multiqc/multiqc_report.html: a standalone HTML file that can be viewed in your web browser.multiqc_data/: directory containing parsed statistics from the different tools used in the pipeline.multiqc_plots/: directory containing static images from the report in various formats.
MultiQC is a visualization tool that generates a single HTML report summarising all samples in your project. Most of the pipeline QC results are visualised in the report and further statistics are available in the report data directory.
Results generated by MultiQC collate pipeline QC from supported tools e.g. FastQC. The pipeline has special steps which also allow the software versions to be reported in the MultiQC output for future traceability. For more information about how to use MultiQC reports, see http://multiqc.info.
Pipeline information
Output files
pipeline_info/- Reports generated by Nextflow:
execution_report.html,execution_timeline.html,execution_trace.txtandpipeline_dag.dot/pipeline_dag.svg. - Reports generated by the pipeline:
pipeline_report.html,pipeline_report.txtandsoftware_versions.yml. Thepipeline_report*files will only be present if the--email/--email_on_failparameter’s are used when running the pipeline. - Reformatted samplesheet files used as input to the pipeline:
samplesheet.valid.csv. - Parameters used by the pipeline run:
params.json.
- Reports generated by Nextflow:
Nextflow provides excellent functionality for generating various reports relevant to the running and execution of the pipeline. This will allow you to troubleshoot errors with the running of the pipeline, and also provide you with other information such as launch commands, run times and resource usage.